制作一个情人节动画给心爱的人
如果你在用 firefox 1.5+, Opera 9+,可以去看这个 Demo:
更进一步,如果他/她的手机支持 SVG Tiny 1.1,还可以制作一个 svg 通过彩信发过去。
制作页面就在 http://www.svghearts.com/,可惜不支持中文
另:用 firefox 3(beta4pre) 浏览 svg 的性能明显比 firefox 2 要好不少;而 Opera 对字体的 anti-alias 处理是最赞的。

如果你在用 firefox 1.5+, Opera 9+,可以去看这个 Demo:
更进一步,如果他/她的手机支持 SVG Tiny 1.1,还可以制作一个 svg 通过彩信发过去。
制作页面就在 http://www.svghearts.com/,可惜不支持中文
另:用 firefox 3(beta4pre) 浏览 svg 的性能明显比 firefox 2 要好不少;而 Opera 对字体的 anti-alias 处理是最赞的。
标题党,绝对的标题党,哈哈
我听说有些邮箱用户不堪英文垃圾邮件的骚扰,于是反馈:能不能不要接收英文的邮件...看来这个 gmail 用户现在也有同样的困扰
虽然很久以前就尝试使用 glib 库,但还从来没有在多线程环境下使用过它。直到现在在团队内推 glib 的时候才发现 gstring 有线程不安全问题,结果还亏得同事去看 glib 源代码才发现原因所在,:PP
另:今天发现 Intel 发布的两个 top 工具,一个 LatencyTOP,一个 PowerTOP;看起来都是非常的有用..
从 http://blog.daviesliu.net/2005/05/18/192847/ 的留言里面找到 scaner(我想留言的这个is应该就是'一个好白萝卜的坑') 写的一个 python 程序:http://scaner.googlepages.com/iplocater_20060301.py
下载后首先试的是我刚工作那2年长期占据的静态 IP: 202.113.18.2,就发现了结果有乱码,对比着 Luma 关于 QQWry.Dat 格式的文档,写了一个小 patch,目前工作良好
不过还是觉得这种二分查找法稍微慢了点,最好是能把所有数据 load 到一棵 radix tree 里面去,这两天有空试试看
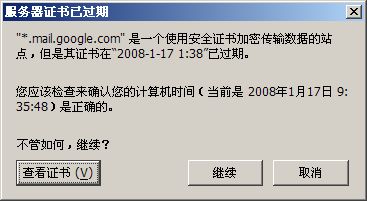
:)
周末因为国民党立法委员选举大败民进党,从而准确地预测到台湾股市大涨。却没有联想到连带福建版块和三通概念股也会大涨。
厦门港务(000905)和厦门空港(600897)连续两天都是涨停。
还是不够敏感啊!继续修炼ing……

虽然已经有瑞士军刀USB闪盘在前,但看到 Swarovski 的东西那叫一个惊艳。
兴冲冲的告诉老婆这东西的存在,但被告知更喜欢 LG-Prada 手机(同时也更贵),立刻心里拔凉拔凉的
另一个好东西是 D-Link 的数字相框。我确实很喜欢这个主意:把数码相片通过 RSS 发布,然后在湖北的爷爷奶奶,在天津的姥姥姥爷,就可以很方面的透过这个产品看到我们达达最新的成长照片啦。
如果有什么节日祝贺也不要用短信或电话这么恶俗的工具,直接用手写板写上祝福语,转成图片更新过去就成了。
不知道这玩意儿耗电怎么样,俺们可是要建设节约型社会的啊...
我家有5块硬盘,除了笔记本里的那块外,还有2个3.5寸,2个2.5寸的躺在硬盘盒里.
昨晚需要用一个3.5'盘里的数据,手忙脚乱的接上线,通电,然后闻到一股糊味,大惊赶快断电,后来检查才发现是变压器烧了,而不是我的硬盘,真是万幸。
但移动硬盘就这么用着,说不定哪天就出了问题。现在硬盘是够便宜了,免费的网络存储服务好像也不少,但怎么还没有一套特别好的家庭存储解决方案呢?
从我自己的需求来讲,我希望的方案是这样的:
* 首先是需要一个很强悍的客户端软件,根据用户每天产生的数据,判断出用户的行为模式,自动去收集整理用户可能要备份的文件* 私人多媒体文件比较麻烦一些。单单说数码照片这部分吧,少量是可以存储在收费服务上的,更多的恐怕是要刻录在光盘上了;因此这个软件需要能对光盘进行管理,包括索引、tag 等等的功能。DV 数据也差不多是如此,需要能对光盘进行管理。
综上所述,该解决方案应该包括:客户端软件从功能上看则大概是 google desktop search、picasa、nero、emule 等等综合起来的一个怪物
驯服这个怪物不是件简单的事情,会有哪个厂商来干这件事情?现在已经有人在做类似的东西了吗??
有时候希望在机器上起一个 web server,用来做文件共享。前两天在邮件列表上看到一个好方法:在希望共享的目录下运行
python -m CGIHTTPServer
BTW: 最近练习《上海滩》中,觉得如果有可以自定义键盘区域音色的电子琴就好了,可以玩两种乐器合奏... 可能这就属于比较专业的设备了.
del.icio.us 有一个 "daily blog posting" 的功能,就是通过 blogapi,每天某个时间自动把内容发表到 blog 上。如果要在 Drupal 站点上启用,步骤如下
1. enable blogapi module
2. 配置 blogapi(admin/settings/blogapi),使之支持 blog 类型的发布
3. Drupal 对 blogapi 的支持和 del.icio.us 不太一样,主要是对 XMLRPC 的数据类型申明不同,需要修改 modules/blogapi/blogapi.module:
3.1 找到 metaWeblog.newPost,把它下面第二行的
array('string', 'string', 'string', 'string', 'struct', 'boolean'),改成
array('string', 'int', 'string', 'string', 'struct', 'int'),3.2 找到 mt.setPostCategories,把它下面第二行的
array('boolean', 'string', 'string', 'string', 'array'),改成
array('boolean', 'int', 'string', 'string', 'array'),4. 设置 del.icio.us:
4.1 out_name 和 out_pass 就是用户名和密码
4.2 out_url 是 http://yoursite/xmlrpc.php
4.3 out_time 随便设,我用的是 0,这样每天早晨 8 点自动 post
4.4 out_blog_id 我用 1 (虽然我在 Drupal 里面的 userid 是 3)
4.5 out_cat_id 我就是为其创建了一个专门的 taxonomy/term 的 id
进一步的技术细节:
我发现在启用 blogapi 后,首页里面的 head 标签内就自动增加了一个 type 是 "application/rsd+xml" 的 link 标签,地址是 "http://www.dup2.org/blogapi/rsd",这样支持 blogapi 的软件,比如 MS 的 Live Writer,就可以从中获得该站点支持的 API 类型。
如果不做 hack,del.icio.us 传递的参数将无法被正确识别,会报一个"服务器错误。无效的方法参数" (server error. invalid method parameters)


 本站的feed
本站的feed
最新评论